
Chinese AI Developer Launches DeepSeek-V3, A New ‘Powerful’ AI Model
Discover a new and groundbreaking AI model with 671 billion parameters, offering users improved coding and text generation capabilities. Learn more about its unique architecture that reduces costs while outperforming other open-source AI models across significant benchmarks.
DeepSeek, a Chinese AI developer, introduced DeepSeek-V3 (as what appears to be one of the most advanced AI models) with 671 billion parameters, under a permissive license, allowing developers to download, use, and modify it for commercial uses and other applications.
What DeepSeek-V3 Can Do
The large language model (LLM) can perform various tasks, such as creating software codes and generating texts. The developer claims it can also outperform two other advanced open-source LLMs across over half a dozen benchmark tests.
Based on a combination of "mixture of experts” (MoE) architecture, it comprises multiple neural networks - each being optimized to perform a different set of tasks. It’s unique in the sense that it works with a router, which sends the user’s request to a specific neural network that can best answer the prompt.
Its architecture can reduce hardware costs, limiting the amount of infrastructure to run, because each request is routed straight to a particular neural network to handle a request instead of activating the entire LLM. Each neural network comprises 34 billion parameters.
What’s New in DeepSeek-V3?
-
Improved capabilities
-
3x faster than V2 @ 60 tokens/second
-
Fully open-source models & papers
-
API compatibility intact
-
37B activated parameters
-
671B MoE parameters
-
Trained on 14.8T high-quality tokens
SOURCE: APIDocs DeepSeek News
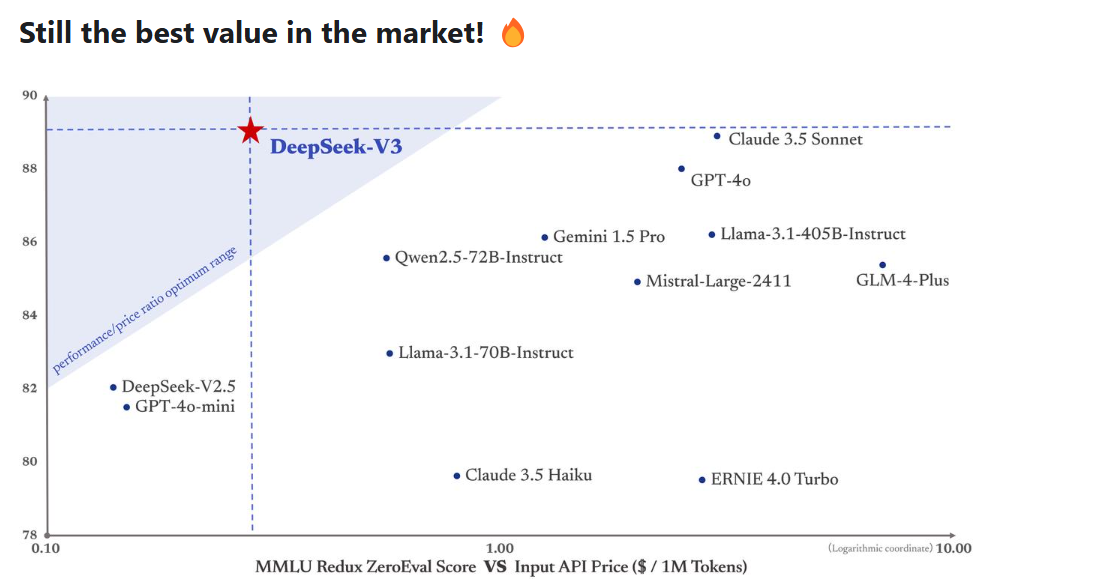
However, DeekSeek- V3 has its fair share of downsides. For instance, some of the model’s neural networks receive a higher amount of training data compared to the others. This can result in output quality inconsistencies, as you can imagine. The developer says it’s developed ways to address this issue and that it’s implemented it in V3.
Pricing

In training, it used only a little infrastructure - 2.788 million graphics processing unit (GPU) hours.
[Data Science: A token is used to represent bits of raw data with one million tokens equivalent to about 750,000 words.]
DeepSeek-V3 also presents better output quality, thanks to several optimizations it was designed with. It uses ‘attention,’ a technique to identify a sentence’s most important details.
The AI implements multi-head latent attention, allowing it to extract the primary details from a text snippet a couple of times to ensure it reduces the likelihood of missing essential information.
In addition, the LLM features multi-token prediction compared to most language models, which generate text with only one token at a time, allowing it to make quicker inferences.
The developer tested and compared it to three other open-source LLMs - Qwen2.5 72B, Llama 3.1 405B, and DeepSeek-V2, with V3 achieving higher scores across nine benchmarks, including math and coding used in the evaluation, while also performing well at a range of text processing.
Useful Resources
Keep reading
More from the blog on the same topic.

A Chinese Startup's New AI Model, DeepSeek R1, Shakes the AI World
The AI startup DeepSeek has the tech world talking after releasing two large language models (LLMs) that rival dominant US-developed AI tools.

ElevenLabs Launches Eleven v3 (Alpha): Game-Changing TTS Model
AI audio giant ElevenLabs has officially launched Eleven v3 (Alpha). It is the brand’s most advanced and emotionally expressive TTS (text-to-speech) system to date.

Google Unveils Gemma 3: A New Benchmark for AI Accessibility
Google launches Gemma 3, a collection of open models the tech giant claims are its most advanced, portable, and “responsibly developed” open model yet. Read more here today!
Ready to create talking videos that hold attention?
Start with a script, pick a puppet, and share a finished video in minutes. Free to try, no credit card required.