OpenAI Text-to-Speech API for Developers: Everything You Need to Know
What’s the OpenAI Text-to-Speech API? Learn everything you need to know today!
The OpenAI Text-to-Speech API (TTS) allows developers to transform text into speech with minimal latency. It is a valuable tool for app developers because it will enable them to create natural-sounding voices from a text file.
This is especially valuable for apps requiring quality voices, such as AI avatars for sales and customer support, accessibility tools, and virtual assistants.
OpenAI TTS API

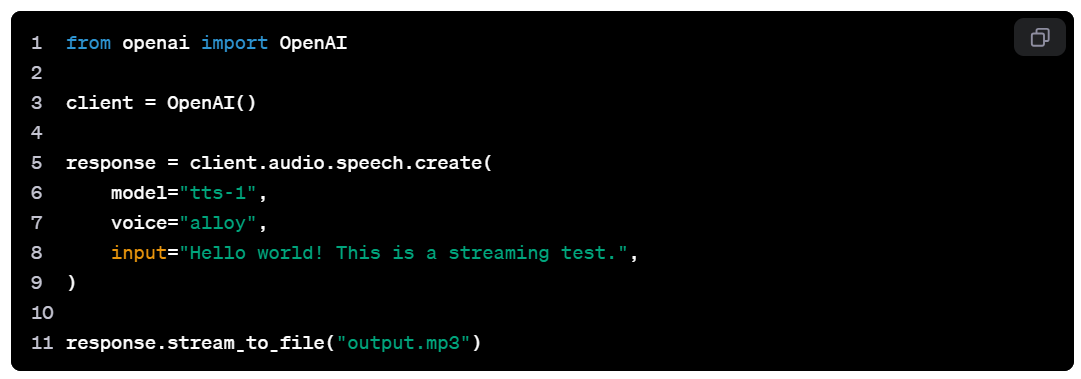
The TTS API allows developers to generate top-notch spoken audio from text. Currently, Open AI offers six preset voices and two model variants - tts-1, which is optimized for real-time use cases, and tts-1-hd, which is optimized for quality.
Also: OpenAI's New Model: “Thinking” ChatGPT Strawberry
OpenAI Features
Customizable voices
Choose a voice and adjust its speed, pitch, and tone based on your needs. Developers can take this further by personalizing their user experiences through choosing multiple voices or trying voice models, such as Shimmer and TTS-1-HD.
Supports multiple languages
This model follows the Whisper model regarding language support while also supporting a wide range of languages listed here. Developers can use this feature for customer service bots, international projects, and multilingual apps.
Low latency and real-time
Apps that need real-time support, including interactive avatars and conversational agents, can apply this TTS API, reducing latency by delivering speech quickly when optimized voices are used.
Compatibility

The TTS API model allows developers to generate speech in formats such as AAC, WAV, FLAC, or PCM, giving them the flexibility to develop Android, iOS, or other web applications.
Transcription’s Whisper Model
Whisper offers transcription that allows audio-to-text conversion. It can combined with text-to-speech for voice-based input or output systems.
Also: AI Video Creators: New Apple Intelligence Features
Custom AI Models
You can pair GPT-3, Turbo, or GPT-4o with OpenAI’s text-to-speech API to ensure dynamic voice is produced. Developers will find it helpful, especially for virtual assistants and chatbots.
OpenAI Text-to-Speech API: Real-World Applications
The following explores its real-world use cases.
Book or blog post narration
Have you completed a book or blog but want to make it more accessible to a wider audience? You can convert it to high-quality audio. Using OpenAI voices, you never need to hire a narrator again or spend time narrating your text. We know this is a tedious process.
The process is easy. You can just pass the text document to the API so that it can start converting text to speech.
Multiple Language Support for Academics, Education, etc.
Educators can use the OpenAI TTS to produce spoken audio in different languages. So, instead of teaching group lessons, the technology can produce personalized lesson materials for students with different dialects or languages.
Even if the TTS model is optimized for English, it can create audio in supported languages, such as French, Korean, and Tagalog.
Users can produce spoken audio in one of the languages by simply providing their input text in their choice language.

Streaming Real-Time Audio
Developers can use the API to create more realistically sounding and expressive voices better than other TTS systems. If you’re a video game developer, you can use and apply this feature to your game characters, giving players a more immersive and exciting experience.
Use OpenAI Voices in Puppetry Today!
Puppetry AI video generator now features OpenAI voices in its premium voices. Video creators, game developers, and marketers can use these voices in their projects! If you’re not yet a member, sign up here.
TTS API: FAQs
How to enable the TTS API?
Register for an OpenAI API key, adjust your settings, and follow API documentation. Use proper endpoints if you want to use special features, such as the Onyx Model, or to transcribe.
How do you adjust or control the emotional range of the generated audio?
No direct mechanisms exist to control the generated audio’s emotional output. Grammar, capitalization, and other factors can influence it. However, OpenAI yielded mixed results based on its internal tests.
Does the API support custom copying of one’s voice?
No, it doesn’t.
How about the ownership of the generated audio files?
The user who created the outputs owns the output. However, they should still inform their listeners, viewers, or audience in general that AI is the audio they’re hearing, not an actual human.
How to use TTS API?
You can access and use the latest audio-speech endpoint provided you have an OpenAI API account.
Is the TTS API free?
No, it’s not. The price depends on volume and usage. Refer to the documentation for a cost breakdown, which is based on the number of audio minutes generated or the number of characters.
What’s the input size max that I can submit/request?
At default speed, it’s equivalent to ~5 audio minutes or 4096 characters.
Keep reading
More from the blog on the same topic.

GPT4o: Everything You Need to Know 2024
Just as everyone thinks GPT-4 is already a game changer, OpenAI surprises AI fans and experts with yet another revolutionary AI tool – GPT-4o. Learn more today!
Apple Intelligence Features: What You Need to Know
Apple Intelligence can transform your experiences with innovative, advanced AI, enhanced automation, and personalized suggestions. Stay ahead. Read this post about its latest features!

AI for Freelancers: How to Stay Updated & What to Learn 2024
Are you a freelance content creator? Keep up with the changes and improve your AI knowledge. Here's how to stay updated with AI and what you can learn from it.
Ready to create talking videos that hold attention?
Start with a script, pick a puppet, and share a finished video in minutes. Free to try, no credit card required.